🎧 Presentazione del progetto
Il progetto si propone di sviluppare un sistema intelligente per la protezione uditiva e la comunicazione in ambienti di lavoro rumorosi, utilizzando un’infrastruttura IoT composta da Raspberry Pi, cuffie Bluetooth e beacon BLE.
L’obiettivo è monitorare il livello di pressione sonora dell’ambiente e attivare un filtro elettronico in caso di superamento di una soglia configurabile. Durante questa fase di insonorizzazione, se l’operatore parla, la voce viene convertita in testo tramite un sistema di Speech-To-Text e trasmessa agli altri operatori nelle vicinanze. La comunicazione viene poi riprodotta vocalmente tramite Text-To-Speech, garantendo una comunicazione efficace senza compromettere la sicurezza.
Il sistema riduce il carico cognitivo e fisico associato all’uso di chat o comandi vocali diretti, mantenendo la comunicazione fluida e discreta. A differenza delle soluzioni esistenti, questo approccio passivo permette di continuare a interagire con i colleghi senza dover rimuovere le cuffie o interrompere le operazioni.
🔧 Tecnologie e prototipazione
Il sistema sfrutta dispositivi commerciali già disponibili, come cuffie Bluetooth a basso costo, e l’attenuazione del rumore viene attualmente simulata per la validazione della logica progettuale. L’architettura software è comunque pensata per essere integrabile in un prodotto reale.
Il progetto si inserisce pienamente nell’ambito IoT, grazie all’uso di:
- Dispositivi connessi e wearable
- Sensori acustici e beacon BLE
- Elaborazione dei dati in tempo reale
- Tecnologie di comunicazione vocale automatica
Si ispira inoltre ai principi della Safety Technology, migliorando la sicurezza sul lavoro in ambienti industriali critici e rumorosi, e della Wearable Technology, favorendo un’interazione continua e naturale con il sistema.
📦 Repository GitHub
Il progetto è suddiviso in più componenti, ciascuno con il proprio repository:
- STT-Broadcast – Monitoraggio rumore e riconoscimento vocale → GitHub Repo
- Mobile-App – Applicazione Mobile → GitHub Repo
- TTS-Receiver – Ricezione e sintesi vocale del testo in arrivo → GitHub Repo
🏗️ Architettura
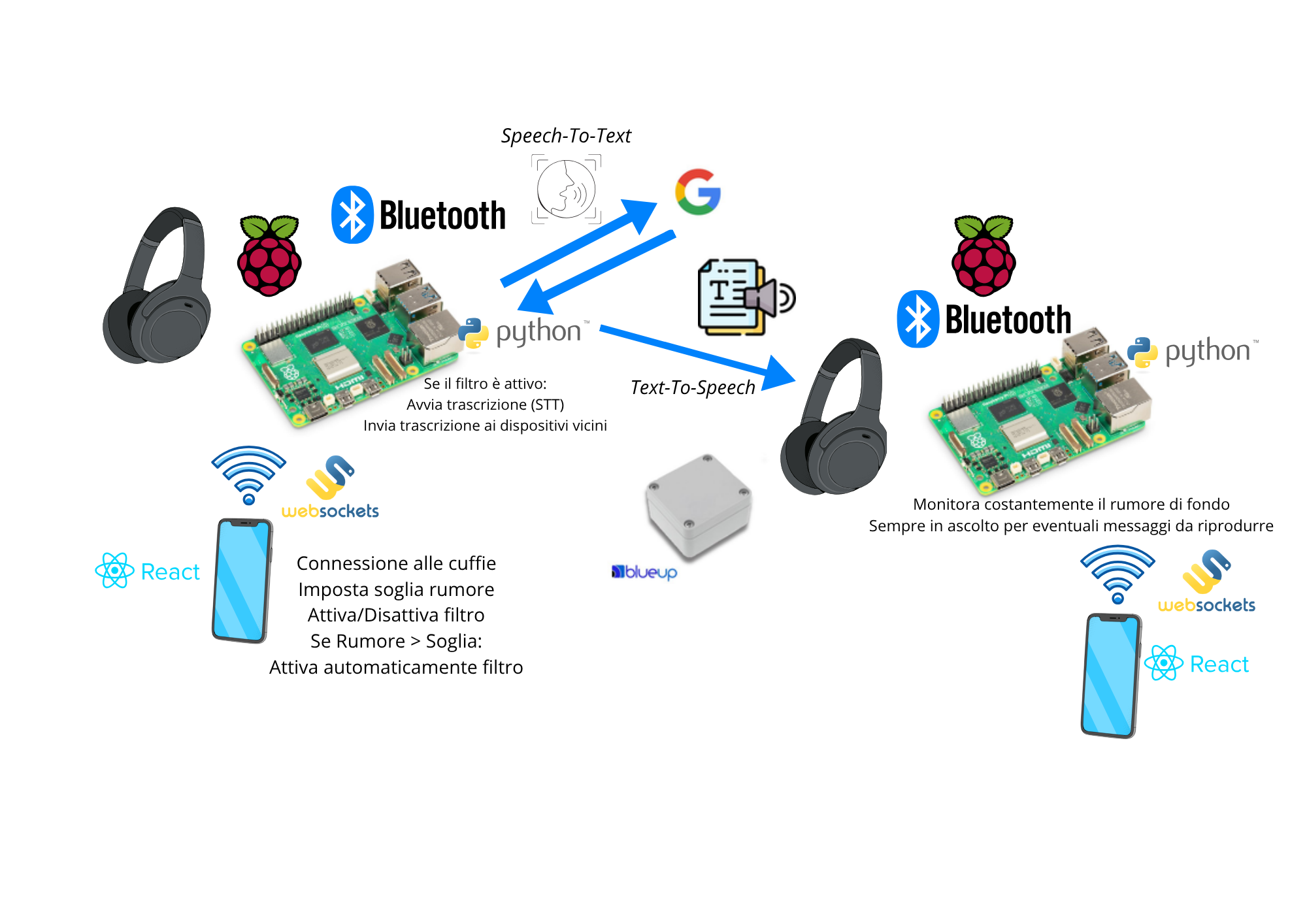
L’architettura del sistema è raffigurata nel diagramma seguente:
📡 Descrizione
Il sistema è progettato per garantire comunicazioni vocali efficaci in ambienti ad alto rumore, proteggendo al contempo l’udito degli operatori. La logica si basa su una rete di cuffie Bluetooth intelligenti, Raspberry Pi 5 e beacon BLE, che lavorano in sinergia per monitorare il rumore e abilitare la comunicazione vocale trasformata in testo.
🔁 Flusso operativo
-
Rilevamento del rumore
Le cuffie, dotate di microfoni integrati, misurano costantemente il livello di pressione sonora ambientale in dB(A).
Al superamento di una soglia configurabile, viene attivato un relè che simula la chiusura del filtro acustico. - Elaborazione vocale
In modalità di isolamento:- L’audio dell’operatore viene acquisito.
- Il Raspberry Pi elabora il segnale e lo converte in testo tramite tecnologie di Speech-To-Text (STT).
- La trascrizione viene trasmessa via Bluetooth agli altri operatori presenti nella stessa zona operativa.
-
Identificazione della prossimità
I beacon Bluetooth Low Energy (BLE) consentono di identificare gli operatori nella stessa area, garantendo l’invio mirato delle trascrizioni vocali. - Ricezione e sintesi vocale
I dispositivi riceventi (cuffie) convertono il testo in voce sintetica tramite moduli Text-To-Speech (TTS), consentendo una comunicazione chiara e non intrusiva anche in ambienti acusticamente critici.
📱 Componente mobile
È stata sviluppata un’app mobile (basata su Expo Go) che consente di:
- Regolare la soglia di attivazione del filtro acustico.
- Attivare o disattivare manualmente il filtro.
- Monitorare lo stato operativo del dispositivo.
🔧 Componenti principali
| Componente | Descrizione |
|---|---|
| Cuffie con microfono integrato | Misurano il rumore ambientale e attivano il filtro acustico. Gestiscono anche STT e TTS per la comunicazione tra operatori. |
| Beacon Bluetooth (BLE) | Identificano la posizione relativa degli operatori per abilitare comunicazioni mirate. |
| Raspberry Pi 5 | Elabora i segnali audio, gestisce STT/TTS, gestisce le comunicazioni e l’interfaccia con l’app mobile. |
| App Mobile (Expo Go) | Permette la configurazione della soglia di rumore e il controllo del filtro tramite interfaccia grafica. |
⚙️ Funzionalità
Il sistema SpeechSafe offre un set di funzionalità progettate per garantire protezione uditiva e comunicazione efficace in ambienti di lavoro ad alta rumorosità. Le funzionalità principali includono:
🔊 Monitoraggio del rumore in tempo reale
Le cuffie integrano microfoni che misurano costantemente il livello di pressione sonora ambientale, espresso in dB(A). Il monitoraggio è continuo e permette un intervento automatico al superamento di soglie configurabili.
🚨 Attivazione automatica del filtro acustico
Quando il livello di rumore supera una soglia predefinita:
- Viene attivato un relè collegato a un dispositivo di protezione (simulato tramite segnale acustico/beep).
- L’operatore viene isolato acusticamente, garantendo la protezione uditiva.
🗣️ Comunicazione vocale asincrona (STT/TTS)
Durante la fase di insonorizzazione:
- L’audio registrato dalle cuffie viene convertito in testo tramite tecnologia Speech-To-Text (STT).
- La trascrizione viene inviata in broadcast a tutti gli operatori presenti nella stessa zona, determinata tramite beacon BLE.
- I messaggi ricevuti vengono riconvertiti in voce sintetica tramite Text-To-Speech (TTS), consentendo una comunicazione efficace senza la necessità di rimuovere i dispositivi.
📱 Gestione remota tramite app mobile
È disponibile un’applicazione mobile (sviluppata con Expo Go) che consente di:
- Impostare e regolare la soglia di attivazione del filtro.
- Attivare o disattivare manualmente il sistema di protezione.
- Connettere o disconnettere il dispositivo dal Raspberry Pi.
- Visualizzare lo stato operativo delle cuffie in tempo reale.
📌 Casi d’uso
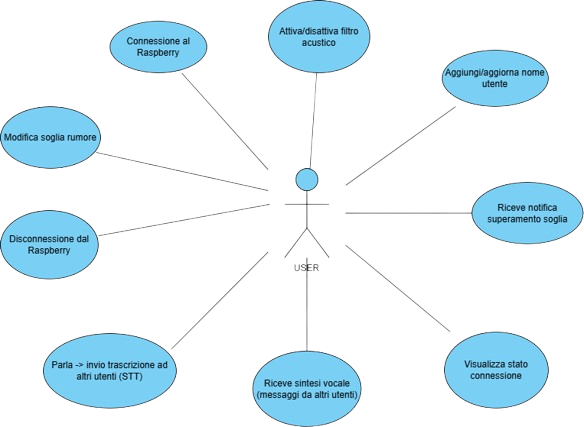
🗂️ Diagramma UML dei Casi d’Uso
🔧 Sviluppo
Il progetto SpeechSafe è stato sviluppato utilizzando un insieme eterogeneo di tecnologie hardware e software, per garantire l’elaborazione in tempo reale dei segnali audio e una comunicazione efficace tra gli operatori.
🔧 Tecnologie utilizzate
🐍 Backend & Elaborazione Audio (Raspberry Pi)
- Python: linguaggio principale utilizzato per sviluppare gli script di monitoraggio del rumore, riconoscimento vocale (STT), ricezione dei messaggi e sintesi vocale (TTS).
- SpeechRecognition: libreria Python per il riconoscimento vocale offline/online.
- NumPy: utilizzato per elaborazioni numeriche e medie sul livello sonoro in dB(A).
- pyttsx3: per la sintesi vocale locale, basata sul motore eSpeak.
- Bleak: libreria per il supporto Bluetooth Low Energy (BLE), necessaria per la scansione dei beacon e l’identificazione della zona operativa.
- websockets: utilizzato per la comunicazione in tempo reale tra Raspberry Pi e l’applicazione mobile.
📱 Frontend Mobile
- JavaScript: linguaggio principale dell’interfaccia utente.
- React Native con Expo Go: framework per lo sviluppo cross-platform dell’app mobile.
- L’app permette:
- La connessione e disconnessione al sistema.
- La regolazione della soglia di attivazione del filtro acustico.
- Il monitoraggio dello stato del sistema e la ricezione di notifiche sonore.
🧩 Architettura dello sviluppo
Il sistema si divide in tre macro-componenti:
- Script Python su Raspberry Pi:
- Monitorano costantemente il rumore ambientale.
- Attivano il filtro (simulato) tramite GPIO/relay.
- Eseguono il riconoscimento vocale e inviano trascrizioni agli altri dispositivi.
- Ricevono messaggi da altri utenti e li riproducono via TTS.
- App Mobile (React Native + Expo Go):
- Connette/disconnette il dispositivo al Raspberry Pi.
- Configura la soglia di rumore.
- Mostra notifiche e lo stato della comunicazione.
- Comunicazione via WebSocket:
- Il Raspberry funge da server, riceve e inoltra messaggi da/verso tutti gli utenti.
- La comunicazione è filtrata in base alla presenza nella stessa area, determinata tramite beacon BLE.